Messages HTTP
Les messages HTTP sont le mécanisme utilisé pour échanger des données entre un serveur et un client dans le protocole HTTP. Il existe deux types de messages : les requêtes envoyées par le client pour déclencher une action sur le serveur, et les réponses, la réponse que le serveur envoie suite à une requête.
Les développeur·euse·s créent rarement, voire jamais, des messages HTTP à partir de zéro. Des applications telles qu'un navigateur, un proxy ou un serveur web utilisent des logiciels conçus pour créer des messages HTTP de manière fiable et efficace. La façon dont les messages sont créés ou transformés est contrôlée via des API dans les navigateurs, des fichiers de configuration pour les proxies ou serveurs, ou d'autres interfaces.
Dans les versions du protocole HTTP jusqu'à HTTP/2, les messages sont basés sur du texte, et sont relativement simples à lire et à comprendre une fois que vous vous êtes familiarisé·e avec le format. Dans HTTP/2, les messages sont encapsulés dans un encadrement binaire, ce qui les rend un peu plus difficiles à lire. Cependant, la sémantique sous-jacente du protocole reste la même, vous pouvez donc apprendre la structure et la signification des messages HTTP à partir du format textuel des messages HTTP/1.x, et appliquer cette compréhension à HTTP/2 et au-delà.
Ce guide utilise les messages HTTP/1.1 pour des raisons de lisibilité, et explique la structure des messages HTTP en utilisant le format HTTP/1.1. Nous mettons en avant certaines différences que vous pourriez avoir besoin de décrire pour HTTP/2 dans la section finale.
Note : Vous pouvez voir les messages HTTP dans l'onglet Réseau des outils de développement d'un navigateur, ou si vous affichez les messages HTTP dans la console à l'aide d'outils CLI comme curl (angl.), par exemple.
Anatomie d'un message HTTP
Pour comprendre le fonctionnement des messages HTTP, nous allons examiner les messages HTTP/1.1 et leur structure. L'illustration suivante montre à quoi ressemblent les messages en HTTP/1.1 :

Les requêtes et les réponses partagent une structure similaire :
- Une ligne de départ est une seule ligne qui décrit la version HTTP ainsi que la méthode de la requête ou le résultat de la requête.
- Un ensemble optionnel d'en-têtes HTTP contenant des métadonnées qui décrivent le message. Par exemple, une requête pour une ressource peut inclure les formats autorisés pour cette ressource, tandis que la réponse peut inclure des en-têtes pour indiquer le format effectivement retourné.
- Une ligne vide indiquant que les métadonnées du message sont terminées.
- Un corps optionnel contenant les données associées au message. Il peut s'agir de données POST à envoyer au serveur dans une requête, ou d'une ressource retournée au client dans une réponse. La présence ou non d'un corps dans un message est déterminée par la ligne de départ et les en-têtes HTTP.
La ligne de départ et les en-têtes du message HTTP sont collectivement appelés la tête des requêtes, et la partie qui suit, qui contient son contenu, est appelée le corps.
Requêtes HTTP
Prenons l'exemple suivant d'une requête HTTP POST envoyée après la soumission d'un formulaire sur une page web :
POST /users HTTP/1.1
Host: exemple.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 49
name=FirstName+LastName&email=ssmth%40exemple.com
La ligne de départ dans les requêtes HTTP/1.x (POST /users HTTP/1.1 dans l'exemple ci-dessus) est appelée « ligne de requête » et se compose de trois parties :
<method> <request-target> <protocol>
<method>-
La méthode HTTP (également appelée verbe HTTP) fait partie d'un ensemble de mots définis qui décrivent la signification de la requête et le résultat souhaité. Par exemple,
GETindique que le client souhaite recevoir une ressource en retour, etPOSTsignifie que le client envoie des données à un serveur. <request-target>-
La cible de la requête est généralement une URL absolue ou relative, et est caractérisée par le contexte de la requête. Le format de la cible dépend de la méthode HTTP utilisée et du contexte de la requête. Cela est décrit plus en détail dans la section Cibles de requête ci-dessous.
<protocol>-
La version HTTP, qui définit la structure du reste du message, agissant comme un indicateur de la version attendue pour la réponse. Il s'agit presque toujours de
HTTP/1.1, carHTTP/0.9etHTTP/1.0sont obsolètes. Dans HTTP/2 et au-delà, la version du protocole n'est pas incluse dans les messages car elle est comprise lors de l'établissement de la connexion.
Cibles de requête
Il existe plusieurs façons de décrire une cible de requête, mais la plus courante est la « forme origin ». Voici une liste des types de cibles et quand elles sont utilisées :
-
En forme origin, le destinataire combine un chemin absolu avec l'information de l'en-tête
Host. Une chaîne de requête peut être ajoutée au chemin pour des informations supplémentaires (généralement au formatkey=value). Ceci est utilisé avec les méthodesGET,POST,HEADetOPTIONS:httpGET /fr/docs/Web/HTTP/Guides/Messages HTTP/1.1 -
La forme absolue est une URL complète, incluant l'autorité, et est utilisée avec
GETlors de la connexion à un proxy :httpGET https://developer.mozilla.org/fr/docs/Web/HTTP/Guides/Messages HTTP/1.1 -
La forme autorité est l'autorité et le port séparés par un deux-points (
:). Elle est uniquement utilisée avec la méthodeCONNECTlors de la mise en place d'un tunnel HTTP :httpCONNECT developer.mozilla.org:443 HTTP/1.1 -
La forme astérisque est uniquement utilisée avec
OPTIONSlorsque vous souhaitez représenter le serveur dans son ensemble (*) plutôt qu'une ressource nommée :httpOPTIONS * HTTP/1.1
En-têtes de requête
Les en-têtes sont des métadonnées envoyées avec une requête après la ligne de départ et avant le corps. Dans l'exemple de soumission de formulaire ci-dessus, il s'agit des lignes suivantes du message :
Host: exemple.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 49
En HTTP/1.x, chaque en-tête est une chaîne de caractères insensible à la casse suivie d'un deux-points (:) et d'une valeur dont le format dépend de l'en-tête.
L'ensemble de l'en-tête, y compris la valeur, tient sur une seule ligne.
Cette ligne peut parfois être très longue, comme pour l'en-tête Cookie.

Certains en-têtes sont exclusivement utilisés dans les requêtes, tandis que d'autres peuvent être envoyés à la fois dans les requêtes et les réponses, ou avoir une catégorisation plus spécifique :
- Les en-têtes de requête fournissent un contexte supplémentaire à une requête ou ajoutent une logique supplémentaire sur la façon dont elle doit être traitée par un serveur (par exemple, les requêtes conditionnelles).
- Les en-têtes de représentation sont envoyés dans une requête si le message possède un corps, et ils décrivent la forme originale des données du message ainsi que tout encodage appliqué. Cela permet au destinataire de comprendre comment reconstruire la ressource telle qu'elle était avant sa transmission sur le réseau.
Corps de la requête
Le corps de la requête est la partie d'une requête qui transporte des informations vers le serveur.
Seules les requêtes PATCH, POST et PUT possèdent un corps.
Dans l'exemple de soumission de formulaire, cette partie correspond au corps :
name=FirstName+LastName&email=ssmth%40exemple.com
Le corps de la requête de soumission de formulaire contient une quantité relativement faible d'informations sous forme de paires key=value (clé-valeur), mais un corps de requête peut contenir d'autres types de données attendues par le serveur :
{
"firstName": "Sandra",
"lastName": "Smith",
"email": "ssmth@exemple.com",
"more": "data"
}
ou des données en plusieurs parties :
--delimiter123
Content-Disposition: form-data; name="champ1"
value1
--delimiter123
Content-Disposition: form-data; name="champ2"; filename="exemple.txt"
Text file contents
--delimiter123--
Réponses HTTP
Les réponses sont les messages HTTP qu'un serveur envoie en retour à une requête.
La réponse informe le client du résultat de la requête.
Voici un exemple de réponse HTTP/1.1 à une requête POST qui a créé un·e nouvel·le utilisateur·ice :
HTTP/1.1 201 Created
Content-Type: application/json
Location: http://exemple.com/users/123
{
"message": "Nouvel utilisateur créé",
"user": {
"id": 123,
"firstName": "Personne",
"lastName": "Exemple",
"email": "ssmth@exemple.com"
}
}
La ligne de départ (HTTP/1.1 201 Created ci-dessus) est appelée « ligne d'état » dans les réponses, et se compose de trois parties :
<protocol> <status-code> <reason-phrase>
<protocol>-
La version de HTTP du message.
<status-code>-
Un code d'état numérique qui indique si la requête a réussi ou échoué. Les codes d'état courants sont
200,404ou302. <reason-phrase>Facultatif-
Le texte optionnel après le code d'état est une brève description purement informative de l'état pour aider un·e humain·e à comprendre le résultat d'une requête. La phrase d'état est parfois incluse entre parenthèses (par exemple, « 201 (Created) ») pour indiquer qu'elle est optionnelle.
En-têtes de réponse
Les en-têtes de réponse sont les métadonnées envoyées avec une réponse.
En HTTP/1.x, chaque en-tête est une chaîne de caractères insensible à la casse suivie d'un deux-points (:) et d'une valeur dont le format dépend de l'en-tête utilisé.

Comme pour les en-têtes de requête, il existe de nombreux en-têtes différents qui peuvent apparaître dans les réponses, et ils sont catégorisés comme suit :
- Les en-têtes de réponse qui fournissent un contexte supplémentaire sur le message ou ajoutent une logique supplémentaire sur la façon dont le client doit effectuer les requêtes suivantes.
Par exemple, des en-têtes comme
Serverindiquent des informations sur le logiciel du serveur, tandis queDateprécise quand la réponse a été générée. On trouve aussi des informations sur la ressource retournée, comme son type de contenu (Content-Type), ou la façon dont elle doit être mise en cache (Cache-Control). - Les en-têtes de représentation si le message possède un corps, ils décrivent la forme des données du message ainsi que tout encodage appliqué. Par exemple, la même ressource peut être formatée dans un type de média particulier comme XML ou JSON, localisée dans une langue écrite ou une région géographique particulière, et/ou compressée ou autrement encodée pour la transmission. Cela permet au destinataire de comprendre comment reconstruire la ressource telle qu'elle était avant sa transmission sur le réseau.
Corps de la réponse
Un corps de réponse est inclus dans la plupart des messages envoyés en réponse à un·e client·e.
Dans le cas de requêtes réussies, le corps de la réponse contient les données que le client a demandées dans une requête GET.
S'il y a des problèmes avec la requête du client, il est courant que le corps de la réponse explique pourquoi la requête a échoué, et indique si l'échec est permanent ou temporaire.
Les corps de réponse peuvent être :
- Des corps à ressource unique définis par les deux en-têtes :
Content-TypeetContent-Length, ou de longueur inconnue et encodés par morceaux avecTransfer-Encodingdéfini àchunked. - Des corps à ressources multiples, constitués d'un corps contenant plusieurs parties, chacune contenant une information différente. Les corps multiparties sont généralement associés aux formulaires HTML, mais peuvent aussi être envoyés en réponse à des requêtes de plage.
Les réponses avec un code d'état qui répond à la requête sans avoir besoin d'inclure de contenu, comme 201 Created ou 204 No Content, n'ont pas de corps.
Messages HTTP/2
HTTP/1.x utilise des messages basés sur du texte qui sont simples à lire et à construire, mais cela présente quelques inconvénients.
Vous pouvez compresser les corps des messages avec gzip ou d'autres algorithmes de compression, mais pas les en-têtes.
Les en-têtes sont souvent similaires ou identiques dans une interaction client-serveur, mais ils sont répétés dans les messages successifs sur une connexion.
Il existe de nombreuses méthodes connues pour compresser du texte répétitif de façon très efficace, ce qui laisse beaucoup d'économies de bande passante inexploitées.
HTTP/1.x présente aussi un problème appelé blocage de tête de ligne (HOL), où un·e client·e doit attendre une réponse du serveur avant d'envoyer la requête suivante. Le chaînage HTTP a tenté de contourner ce problème, mais le manque de support et la complexité font qu'il est rarement utilisé et difficile à maîtriser. Plusieurs connexions doivent être ouvertes pour envoyer des requêtes simultanément ; et les connexions chaudes (établies et actives) sont plus efficaces que les connexions froides à cause du démarrage lent de TCP.
En HTTP/1.1, si vous souhaitez effectuer deux requêtes en parallèle, vous devez ouvrir deux connexions :
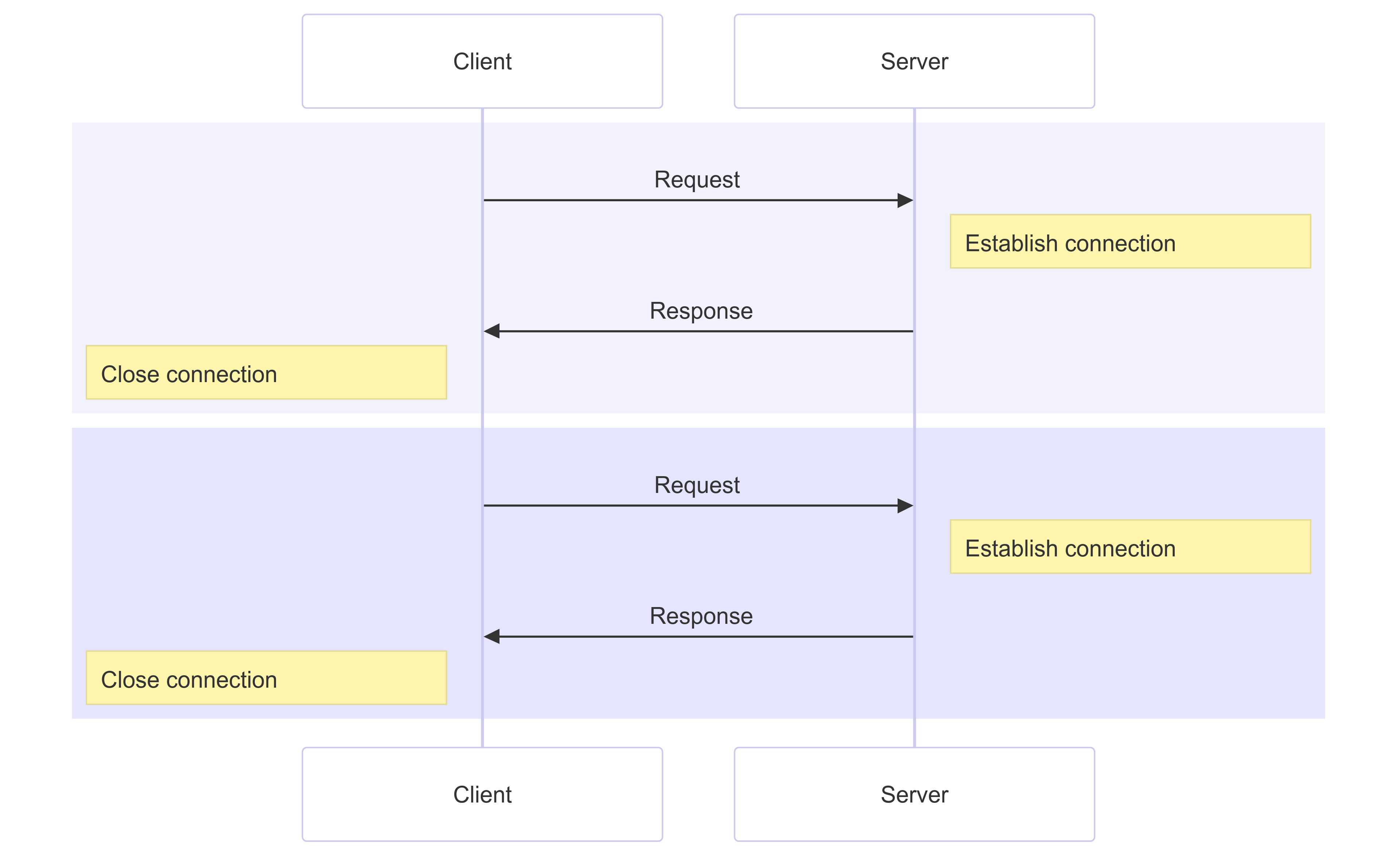
Cela signifie que les navigateurs sont limités dans le nombre de ressources qu'ils peuvent télécharger et afficher en même temps, ce qui est généralement limité à 6 connexions parallèles.
HTTP/2 permet d'utiliser une seule connexion TCP pour plusieurs requêtes et réponses en même temps. Ceci est réalisé en encapsulant les messages dans une trame binaire et en envoyant les requêtes et réponses dans un flux numéroté sur une connexion. Les trames de données et d'en-têtes sont traitées séparément, ce qui permet de compresser les en-têtes via un algorithme appelé HPACK. Utiliser la même connexion TCP pour gérer plusieurs requêtes en même temps s'appelle le multiplexage.
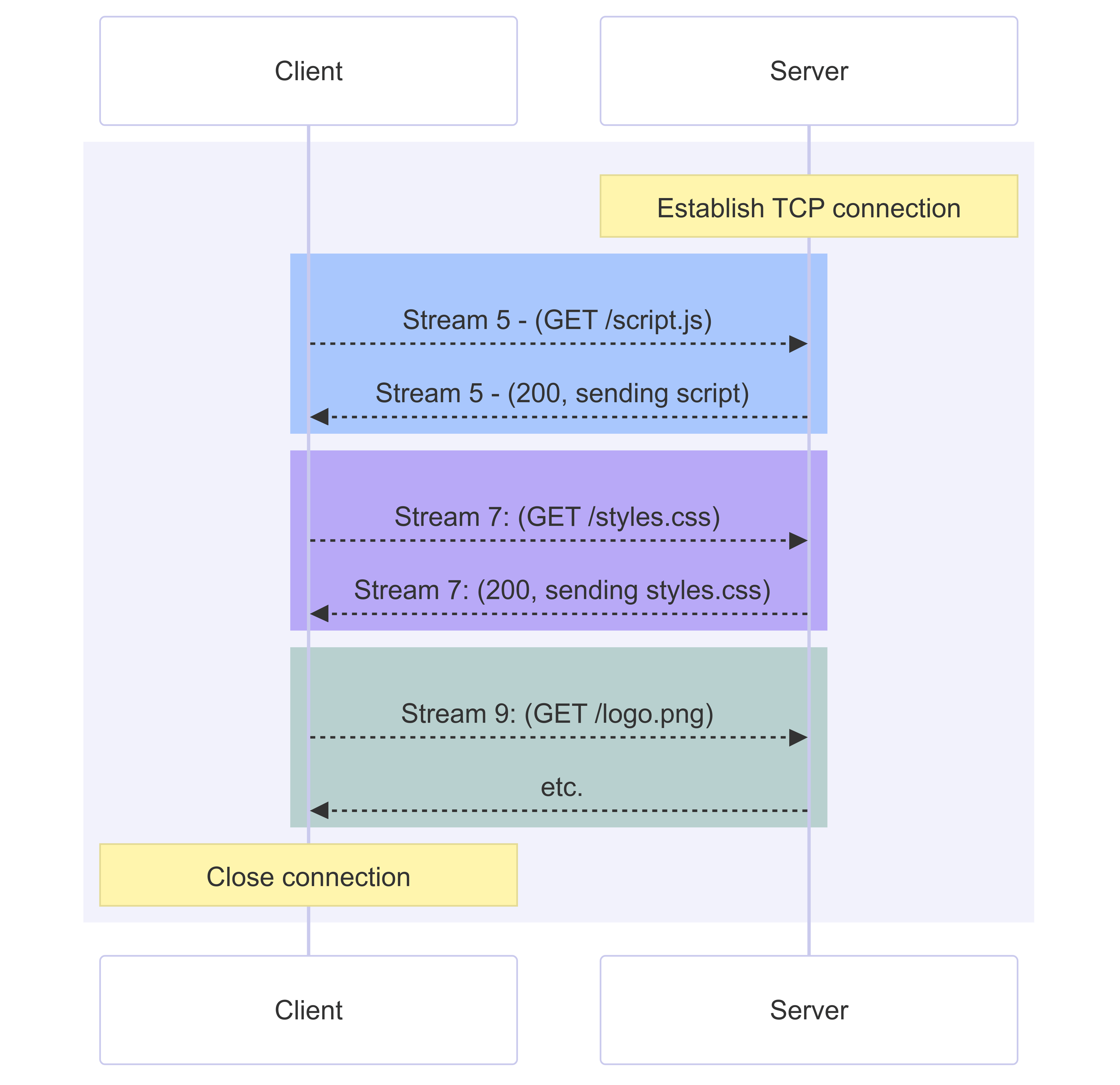
Les requêtes ne sont pas nécessairement séquentielles : le flux 9 n'a pas à attendre que le flux 7 soit terminé, par exemple. Les données de plusieurs flux sont généralement entrelacées sur la connexion, donc les flux 9 et 7 peuvent être reçus par le client en même temps. Le protocole permet de définir une priorité pour chaque flux ou ressource. Les ressources de faible priorité consomment moins de bande passante que celles de priorité élevée lorsqu'elles sont envoyées sur différents flux, ou peuvent être envoyées séquentiellement sur la même connexion si des ressources critiques doivent être traitées en premier.
En général, malgré toutes les améliorations et abstractions ajoutées par rapport à HTTP/1.x, pratiquement aucun changement n'est nécessaire dans les API utilisées par les développeur·euse·s pour utiliser HTTP/2 à la place de HTTP/1.x. Lorsque HTTP/2 est disponible à la fois dans le navigateur et sur le serveur, il est activé et utilisé automatiquement.
Pseudo-en-têtes
Un changement notable dans les messages HTTP/2 est l'utilisation de pseudo-en-têtes.
Alors que HTTP/1.x utilisait la ligne de départ du message, HTTP/2 utilise des champs spéciaux de pseudo-en-tête commençant par :.
Dans les requêtes, on trouve les pseudo-en-têtes suivants :
:method- la méthode HTTP.:scheme- la partie schéma de l'URI cible, souvent HTTP(S).:authority- la partie autorité de l'URI cible.:path- le chemin et la requête de l'URI cible.
Dans les réponses, il n'y a qu'un seul pseudo-en-tête, et c'est :status qui fournit le code de la réponse.
On peut effectuer une requête HTTP/2 avec nghttp (angl.) pour interroger exemple.com, ce qui affichera la requête dans une forme plus lisible.
Vous pouvez lancer la requête avec cette commande, où l'option -n ignore les données téléchargées et -v active le mode verbeux, affichant la réception et la transmission des trames :
nghttp -nv https://www.exemple.com
En parcourant la sortie, vous verrez le minutage de chaque trame transmise et reçue :
[ 0.123] <send|recv> <frame-type> <frame-details>
Il n'est pas nécessaire d'entrer dans tous les détails de cette sortie, mais repérez la trame HEADERS au format [ 0.123] send HEADERS frame ....
Dans les lignes qui suivent la transmission de l'en-tête, vous verrez les lignes suivantes :
[ 0.447] send HEADERS frame ...
...
:method: GET
:path: /
:scheme: https
:authority: www.exemple.com
accept: */*
accept-encoding: gzip, deflate
user-agent: nghttp2/1.61.0
Cela devrait vous sembler familier si vous êtes déjà à l'aise avec HTTP/1.x et que les concepts abordés plus haut dans ce guide s'appliquent toujours.
Il s'agit de la trame binaire contenant la requête GET pour exemple.com, convertie en forme lisible par nghttp.
En descendant plus loin dans la sortie de la commande, vous verrez le pseudo-en-tête :status dans l'un des flux reçus du serveur :
[ 0.433] recv (stream_id=13) :status: 200
[ 0.433] recv (stream_id=13) content-encoding: gzip
[ 0.433] recv (stream_id=13) age: 112721
[ 0.433] recv (stream_id=13) cache-control: max-age=604800
[ 0.433] recv (stream_id=13) content-type: text/html; charset=UTF-8
[ 0.433] recv (stream_id=13) date: Fri, 13 Sep 2024 12:56:07 GMT
[ 0.433] recv (stream_id=13) etag: "3147526947+gzip"
...
Et si vous retirez le minutage et l'identifiant de flux de ce message, cela devrait vous sembler encore plus familier :
:status: 200
content-encoding: gzip
age: 112721
Approfondir les trames de message, les identifiants de flux et la gestion de la connexion dépasse le cadre de ce guide, mais pour comprendre et déboguer les messages HTTP/2, vous devriez être bien équipé·e avec les connaissances et outils de cet article.
Conclusion
Ce guide vous propose une vue d'ensemble de l'anatomie des messages HTTP, en utilisant le format HTTP/1.1 pour l'illustration. Nous avons également exploré le découpage des messages HTTP/2, qui introduit une couche entre la syntaxe HTTP/1.x et le protocole de transport sous-jacent, sans modifier fondamentalement la sémantique de HTTP. HTTP/2 a été introduit pour résoudre les problèmes de blocage de tête de ligne présents dans HTTP/1.x en permettant le multiplexage des requêtes.
Un problème qui subsiste avec HTTP/2 est que même si le blocage de tête de ligne a été corrigé au niveau du protocole, il existe toujours un goulot d'étranglement de performance dû au blocage de tête de ligne dans TCP (au niveau du transport). HTTP/3 corrige cette limitation en utilisant QUIC, un protocole construit sur UDP, au lieu de TCP. Ce changement améliore les performances, réduit le temps d'établissement de la connexion et améliore la stabilité sur les réseaux dégradés ou peu fiables. HTTP/3 conserve la même sémantique HTTP fondamentale, donc des fonctionnalités comme les méthodes de requête, les codes d'état et les en-têtes restent cohérentes sur les trois grandes versions de HTTP.
Si vous comprenez la sémantique de HTTP/1.1, vous avez déjà une base solide pour appréhender HTTP/2 et HTTP/3. La principale différence réside dans la façon dont ces sémantiques sont mises en œuvre au niveau du transport. En suivant les exemples et concepts de ce guide, vous devriez maintenant être en mesure de travailler avec HTTP, de comprendre le sens des messages et la façon dont les applications utilisent HTTP pour envoyer et recevoir des données.
Voir aussi
- Évolution de HTTP
- Mécanisme de mise à niveau du protocole
- Termes du glossaire :